忙完HPCA来填坑 顺便构思一下下个idea
Info
本文作者是KAIST的Zhixian Jin
老板推荐的一篇做GPU架构逆向的文章。文章的主要贡献是通过测量不同SM和L2 cache的访问延迟差异, 从而推断出了GPU的NoC结构, 然后利用这个特性设计了一个side-channel attack。
Introduction && Background
这篇工作是第一个分析现有的商用GPU (其实也就是NV的最近三代卡, V100/A100/H100) 的NoC1, insights在于on-chip latency和bandwidth2有差异, 如果其与物理距离有关, 可用于逆向GPU微架构的物理布局。此发现可以为side channel attack和NoC设计提供一些启示。
Perquisite
讲一下GPU的基础知识, 相关工作和方法论。
目前主流GPU大部分是GPGPU(General-Purpose GPU), 即通用GPU, 衍生自支持可编程着色器的GPU。由于GPU天然高并行的编程范式, 其在AI和HPC中广泛使用。最具代表性的是NV引入的SIMT和CUDA范式。SIMT不同与传统CPU的结构, 其执行单元(ALU)与控制单元(Decoder, PC, etc)不再是一比一; 例如NV GPUs中的一个Warp (线程束) 32个threads (CUDA core) 共享一个PC, 执行同一条指令, 每个threads有一套自己的register; 这也反映出了SIMT的概念: Single Instruction Multiple Threads, 不同的线程执行同一条指令, 当然数据是也是不同的, 非常直观的并行处理。GPU结构从小到大排列是
- CUDA Core/Thread
- Warp
- Streaming Multiprocessor, SM, 有时候叫Core (命名很乱), 有自己的L1 Cache
- Texture Processing Cluster, TPC, 一般由两个SM组成
- Graphic Processing Cluster, GPC
高并行使得GPU对内存带宽需求大, 所以一般GPU会有多个Memory Controller (MC) 来充分发挥HBM的高带宽。NV GPUs 使用Memory Partition (MP) 概念管理3, 每个MP有一块L2 Cache Slice和MC。这些结构间的互联需要复杂且高效的网络, 因此NoC尤为重要。
现有工作分析了Volta和Ampere架构, GPU内存架构和多GPU互联, 但商用GPU内部NoC实现并没有相关分析。
Methodology
首先是测latency, 伪代码如下
size_t* L2_Latency(size_t* D, size_t* M) // D: probe array, M: mapping of L2 slice ID to index of D
{
size_t L[TOTAL_L2][TOTAL_SM]; // malloc
for (int s = 0; s < TOTAL_L2; ++s) {
size_t idx = M[s];
for (int n = 0; n < TOTAL_SM; ++n) {
size_t start = clock();
__ldcg(&D[idx]);
L[s][n] = clock() - start;
}
}
return L;
}
具体实现中, 用-dlcm=cg避免使用L1 Cache, 确保D都在L2内, 并且每一个SM只有一个threads执行; clock()读取cycle计数器, smid寄存器读取SM编号并且可以绑定指定的SM执行, L2 Slice ID 用nvprof工具获取(需要权限)。
对于bandwidth的测量, 对于每个id 为s的L2 slice使用
__kernel void L2_Bandwidth(size_t* D, size_t* M) // M: mappings of L2 slice s to index of D
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = M[tid];
__ldcg(&D[idx]);
}
即同时读s并测量。
Reverse Engineering
Latency
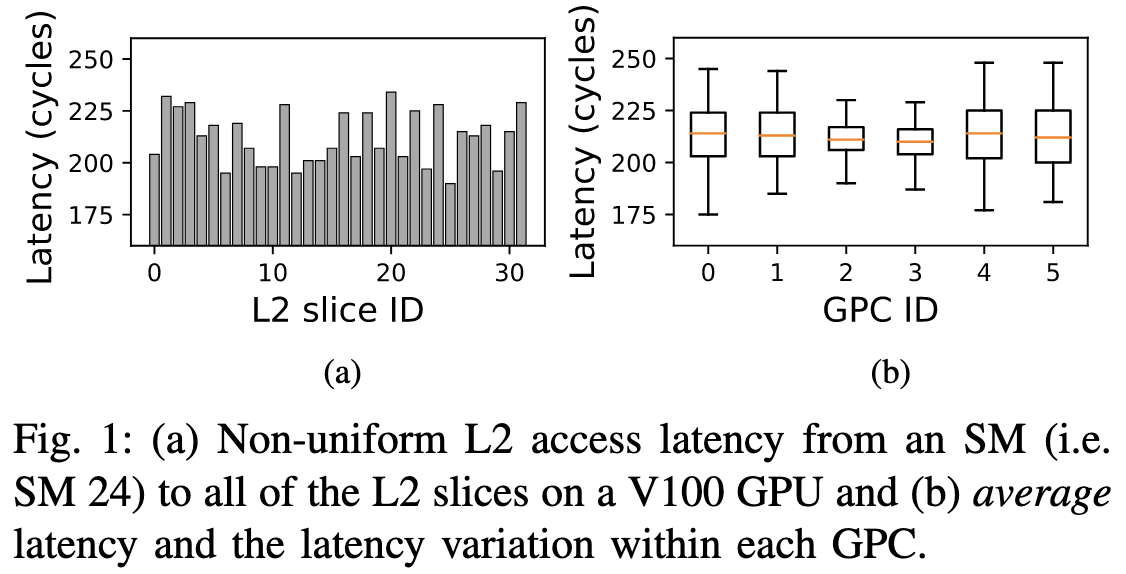
首先是SM访问L2的latency, 其包括SM到NoC的延迟, NoC的传播延迟和L2的延迟。V100中只有NoC的传播延迟是变化的, A100/H100还会有SM到NoC的延迟变化。图1(a)展示了V100中SM 24访问各个L2 Slice的latency差异。虽然每个SM的L2访问延迟都不一致, 但图1(b)说明, SM和GPC的平均访问延迟是大致相同的(得益于NoC的设计)。当然, NoC没法做到让每个GPC得到平等的低延迟, 即使平均上一致, GPC间的方差还是有差异的, 比如图中GPC 2和3明显比较均衡。
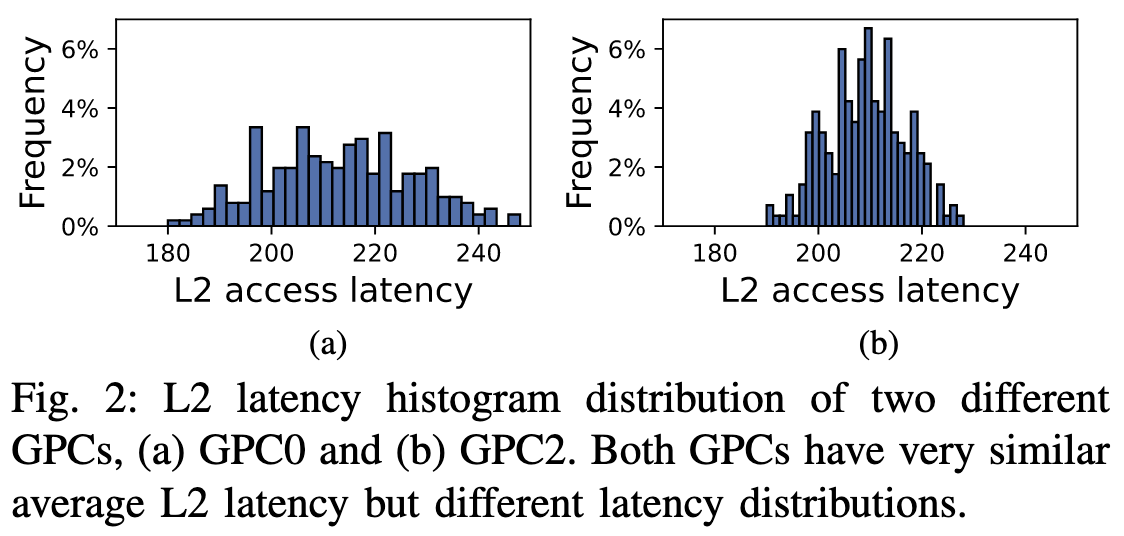
为更详细展示方差的差异, 图2展示不同GPC内的SM访问L2的平均延迟。
前面提到latency展示的pattern可能反映SM的物理布局, 因此作者在图3中对比了同一GPC内的SM和不同GPC的SM, 并按Slice ID排序
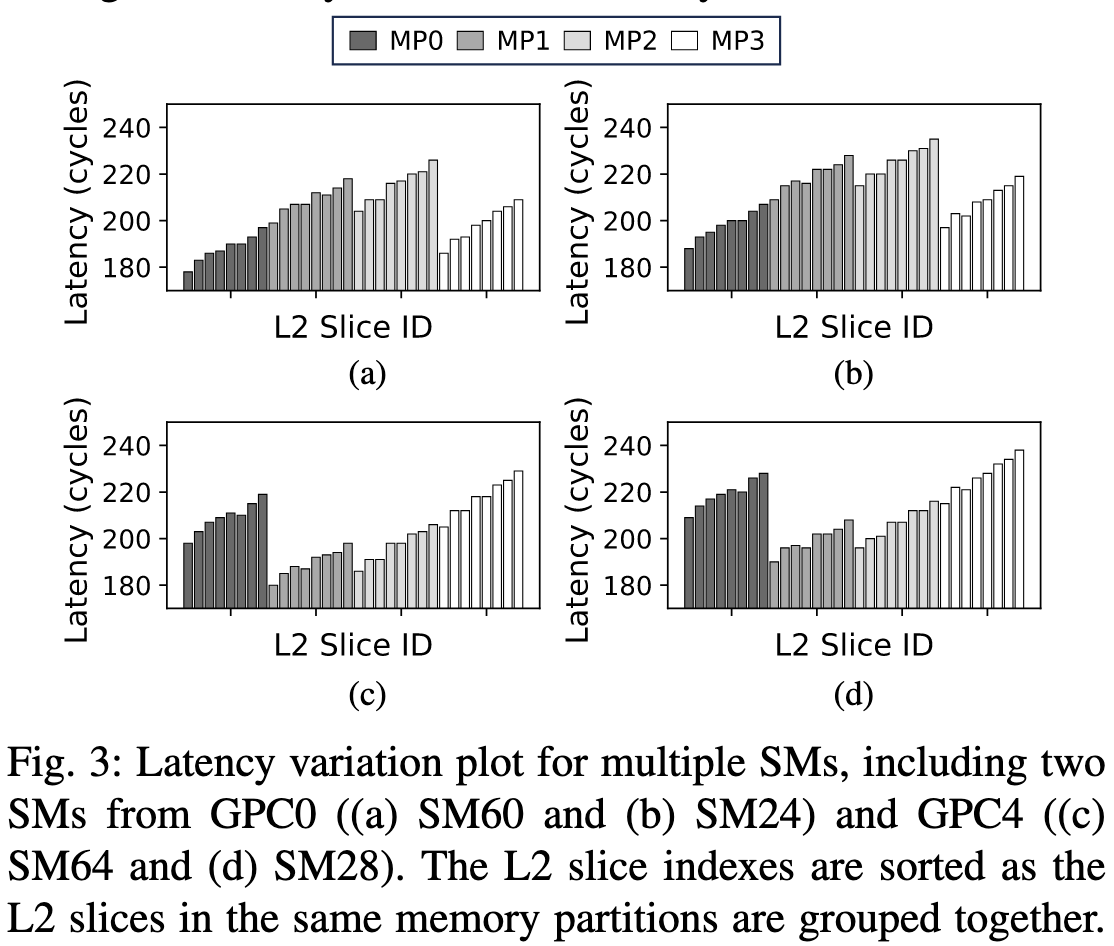
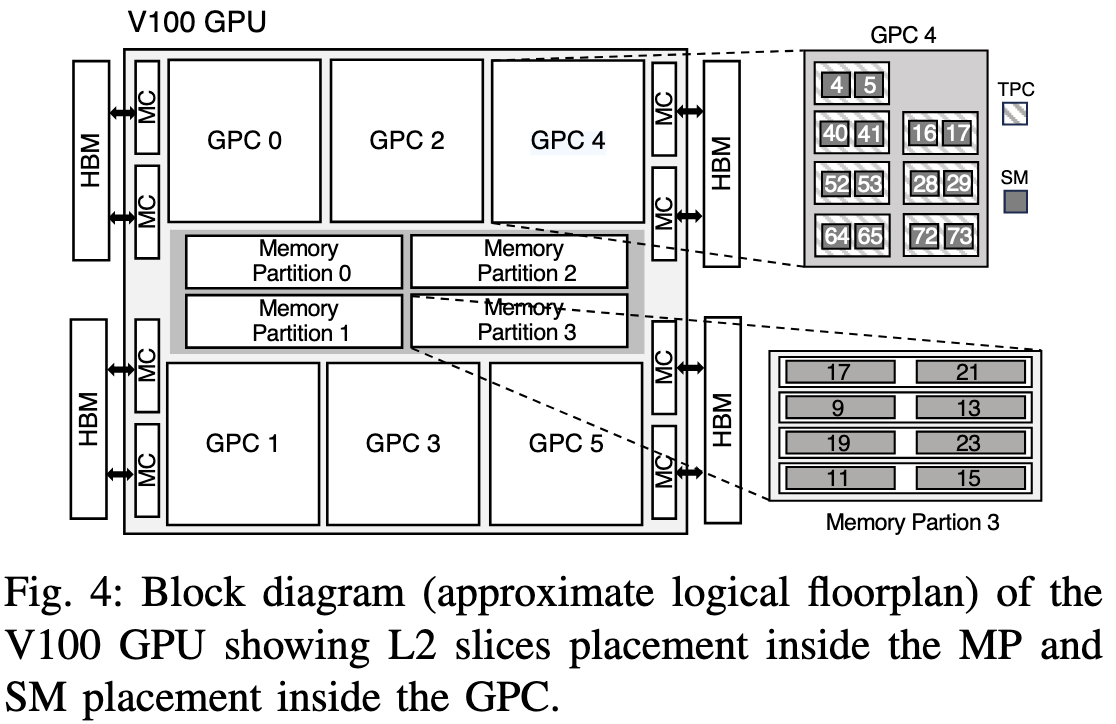
可以看到相同GPC的两个SM(ab和cd)的形状是相似的, 只是实际latency会有差异(base不一样, offset相同); 但不同GPC的SM(比如a和c)的形状就不一样。这印证了作者的猜想。 然后作者整理了一下数据并画出了推测的V100物理布局图
用统计学的方法验证一下, 比如相关系数来衡量一下不同SM的latency分布是否相似, 可以看到图6中V100中同一GPC和相邻GPC的SM分布很接近; 但A100/H100的热力图不太有规律。
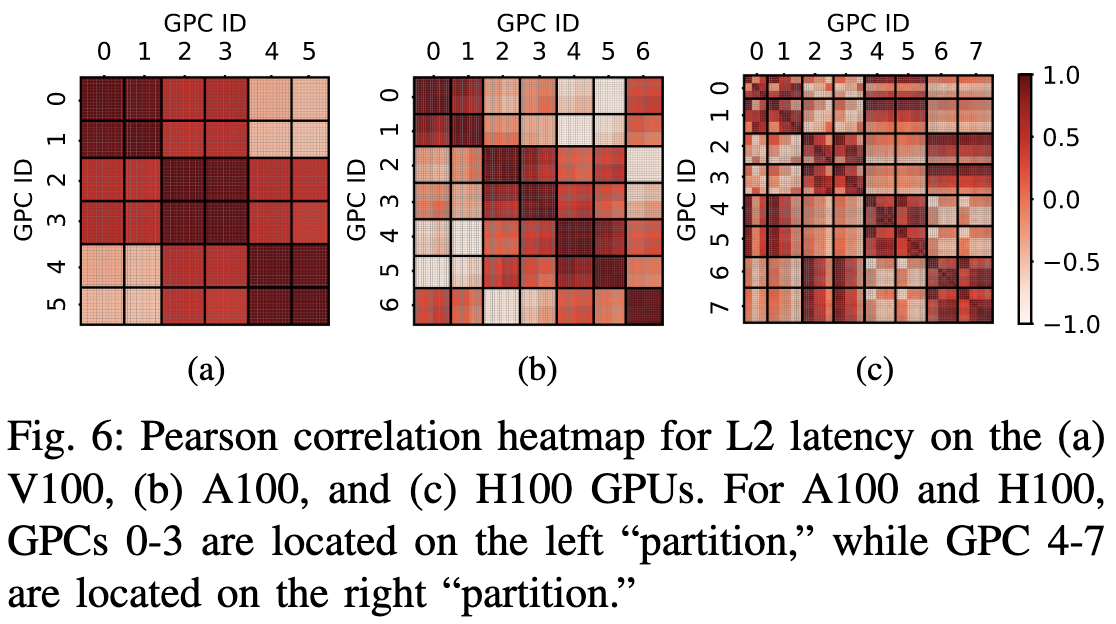
因为A100/H100规模比V100大了很多, 所以有更复杂的层级。民间有传言, Ampere和Hopper在GPC和TPC中还有一个隐藏的层级叫CPC(Compute Processing Cluster), 但CPC在调度上没有任何作用, 只有latency会有差异。为调查此事, 作者用GPC中不同SM访问同一L2 Slice, 并画出了图7。

H100有一个名为distrubted shared memory的新特性4, 所以SM-SM间网络就很大概率会有了, 图7也可以看出来latency能反映物理距离
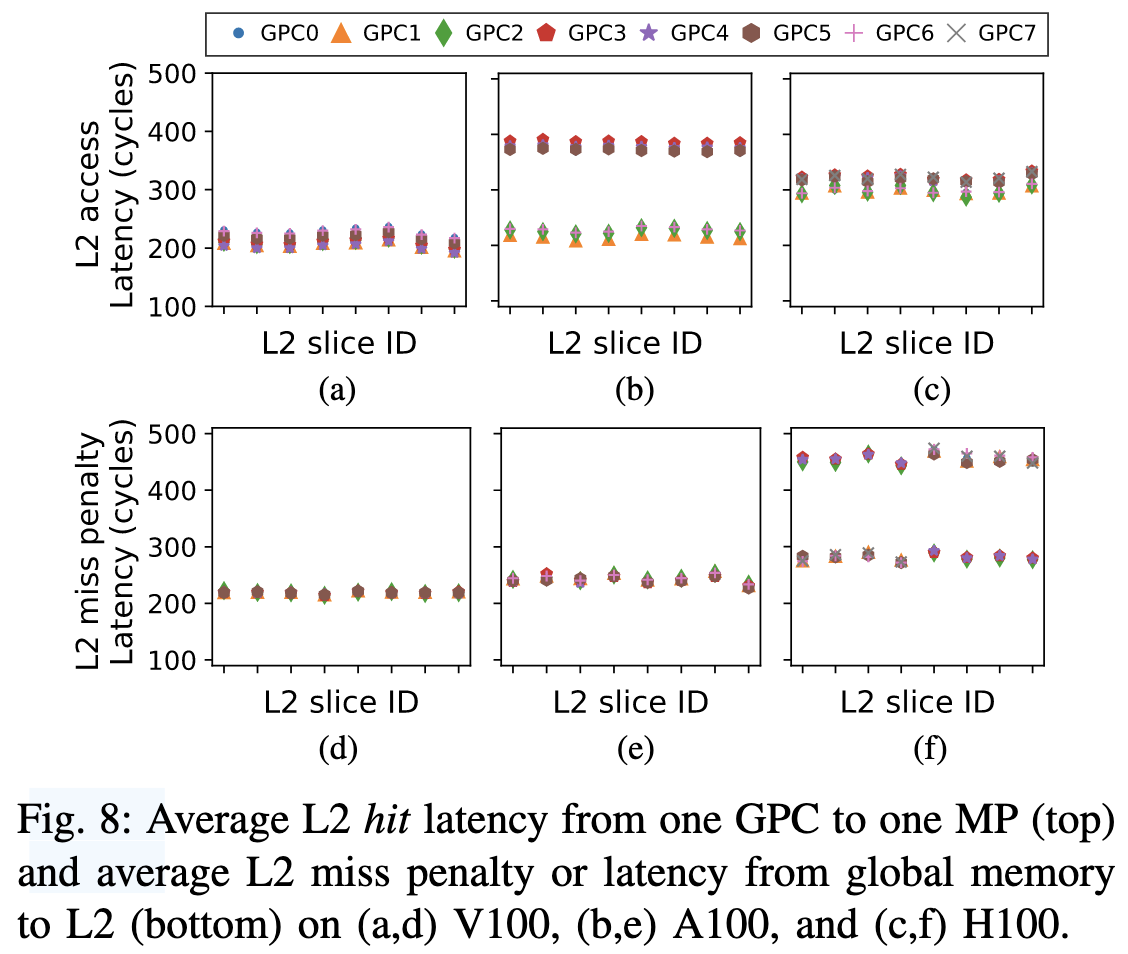
现在的大型GPU可能还有不同的partition, 图8展示了不同GPC的访问某一MP的L2 Hit/Miss延迟, V100和H100的L2 Hit延迟比较相近, 而A100就比较割裂, 作者说这是因为L2 Slice都放在同一个partition内(访问快的partition, GPC 1,2,6,7); H100的Miss/Global Memory访问延迟也比较割裂, 但作者说他也不知道为啥5。
Bandwidth
虽然latency不一致, bandwidth对于每个SM都是相近的。
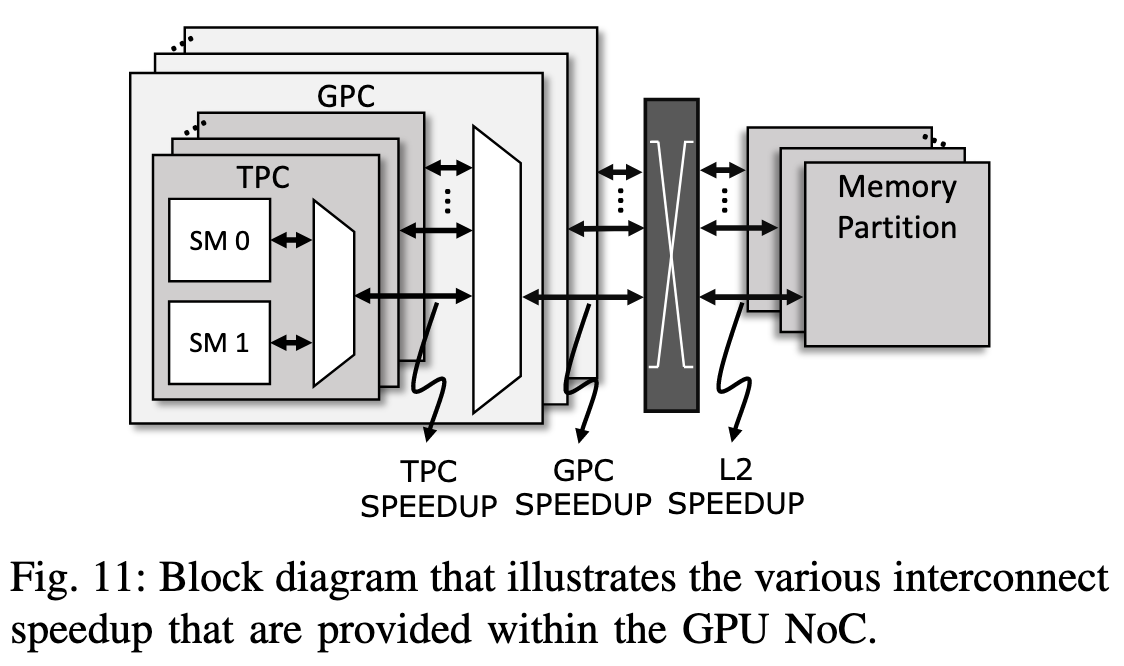
GPU的层级设计一大原因是共享带宽, 所以作者设计了图11中的实验来测量其瓶颈。Speedup的metric是比较$x$个SM(访问L2)的带宽与1个SM的带宽; $x=2$是TPC Speedup, $GPC_{l}$中$x$是TPC数量, $GPC_{g}$则是$2\times$TPC数量6。
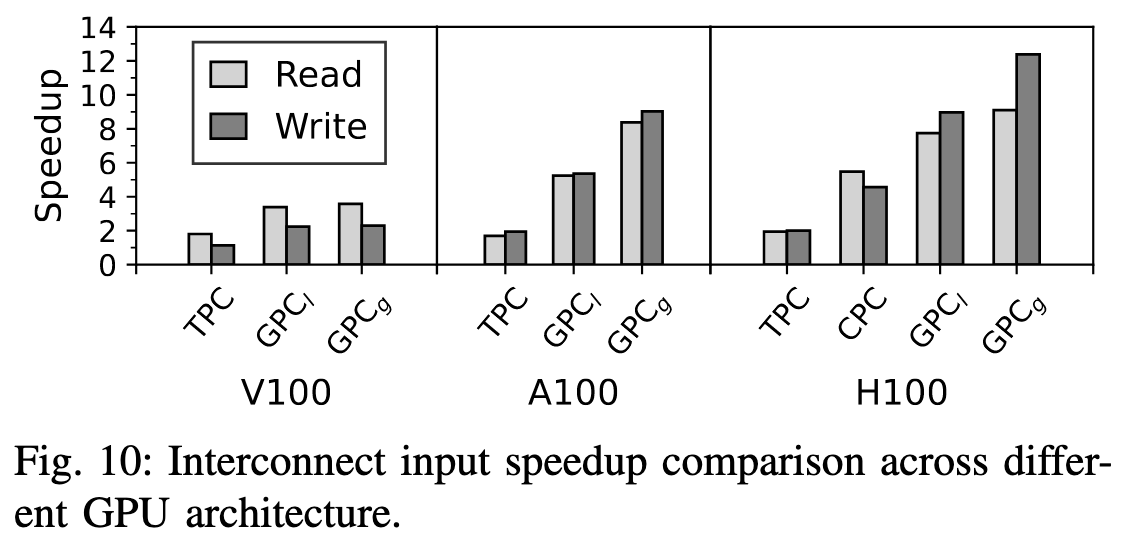
(这图顺序有点怪) 图11可以看出来对read操作, TPC的带宽都是能喂满的; V100中write则不行, 最新两代都可以; 对$GPC_{l}$, V/A/H的满speedup是7, 8, 9, 而V100达到这个要求的50%, H100达到85%。但$GPC_{g}$还能再高一点, 说明瓶颈不在L2上。
前面提到的Ampere有partition, 所以作者还是测了一下这个对bandwidth的影响。结果非常的amazing啊, 访问不同partition的L2 slice带宽居然不一样
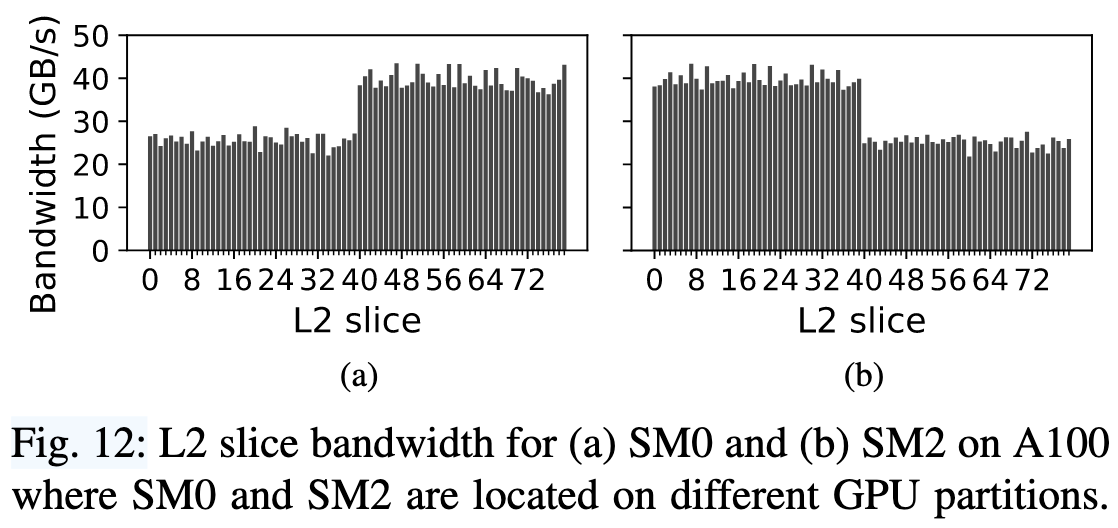
一对比, H100显得又统一了
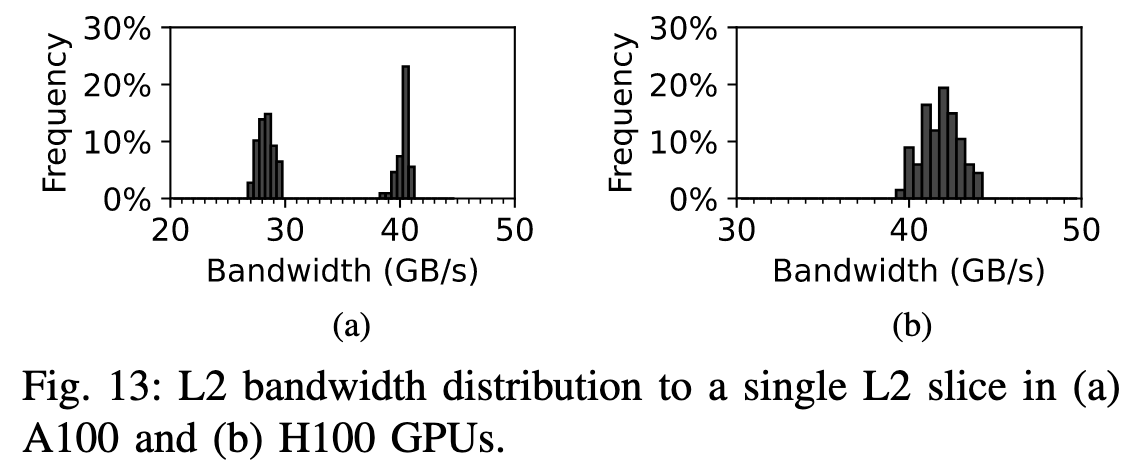
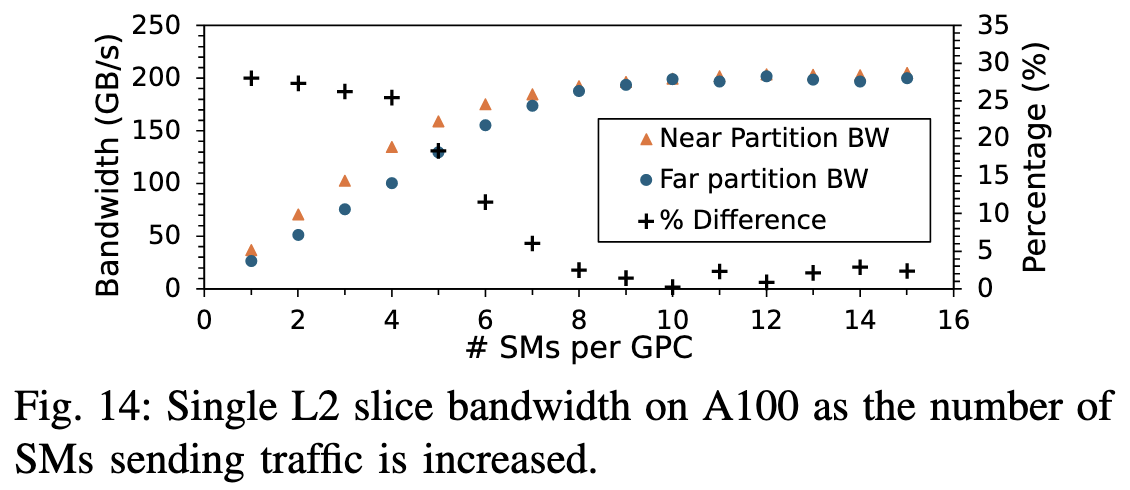
为深入了解A100 partition的影响, 作者又设计了类似的实验。当8个SM并发的时候, partition的影响就不大了。
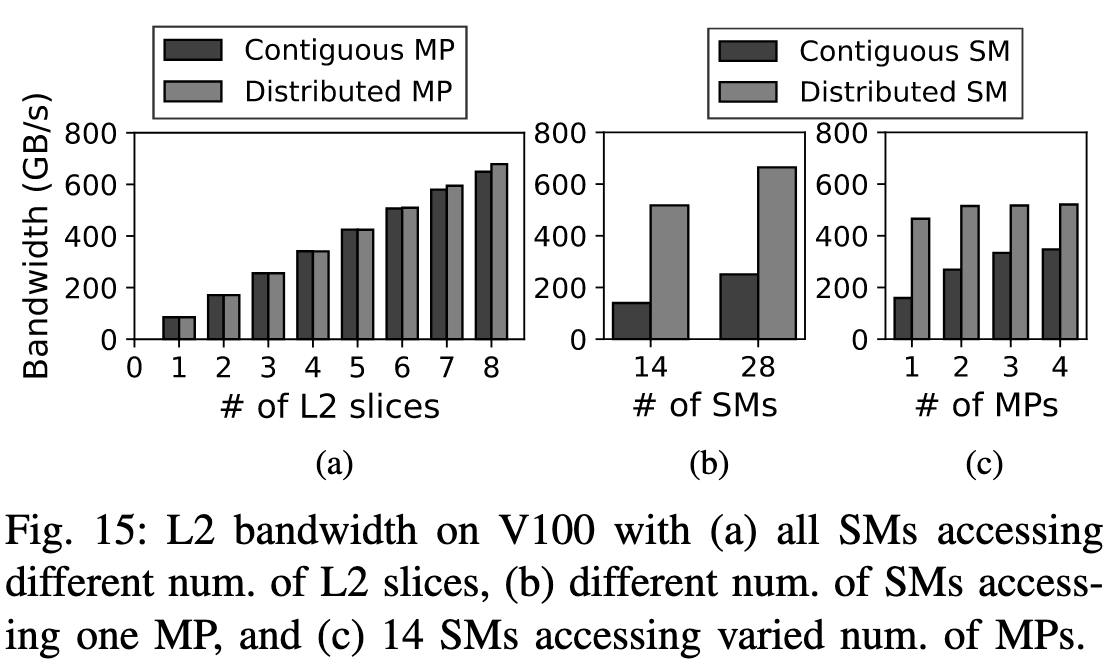
还测了一下MP的瓶颈。Contiguous MP表示访问的L2都是同一MP的, Distributed则是来自不同MP的。图15可以很明显的看出MP的瓶颈: (a)中NoC的共享带宽还是很顶的; (b)中28个(2 GPCs)比14个SM(1 GPC)的增益不多, 作者说是GPC Speedup的瓶颈, 但从14个SM的Contiguous和Distributed的差异很能说明MP的瓶颈; (c)中用Contiguous和Distributed的14个SM访问1-4个MP, 对于Distributed SM(即14个SM来自不同的GPC), MP的数量对带宽影响不大, 瓶颈不在MP, 而Contiguous SM有一倍的提升, 说明一部分GPC Speedup来自于connectivity而不是bandwidth(就是多根线的事)。
Attack & Defense
主要是两个常见的密码学attack, AES和RSA。
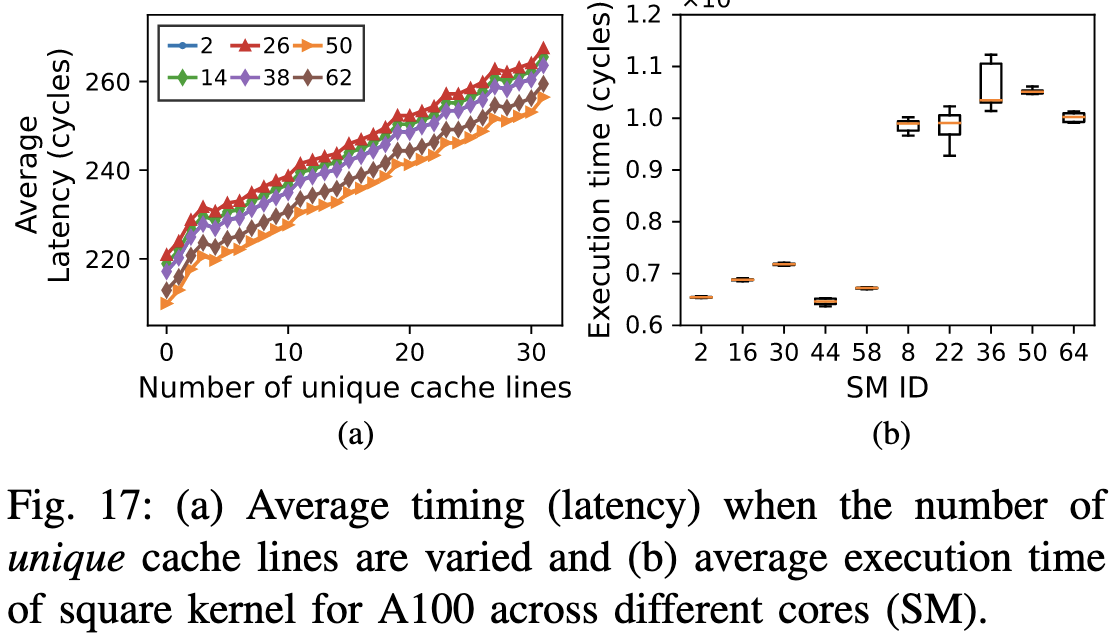
之前针对GPU AES的attack主要集中在
- memory coalescing时latency随着unique cacheline的数量线性增长7, 但不同SM实际的latency会不一样(pattern是一样的)
- 图17(a)中unique cacheline request与latency和SM都有关系, 所以需要确定SM来确定requests

如图18, 前期profiling8并于实际测得的执行时间比对, 然后跟profiling的数据算一下相关系数, 最相关的byte即为key中的其中一个byte
对于RSA, 解密时会用快速幂的方法算, key中bit 0算pow = pow * pow, bit 1时还要多算res += pow, 然后测量执行时间就完事了, 但不同SM执行时间也不一样(图17(b)), 所以也需要确定SM。
Fix
因为问题在于执行kernel的时候SM一般是静态调度, 所以修也很好修, 在CTA调度的时候加个动态和随机就可以了, 效果如图18(b)所示。
Implications
NoC有一个比较常见的问题: Many-to-Few-to-Many, 即"沙漏型"瓶颈, 这个few是指memory controllers不够
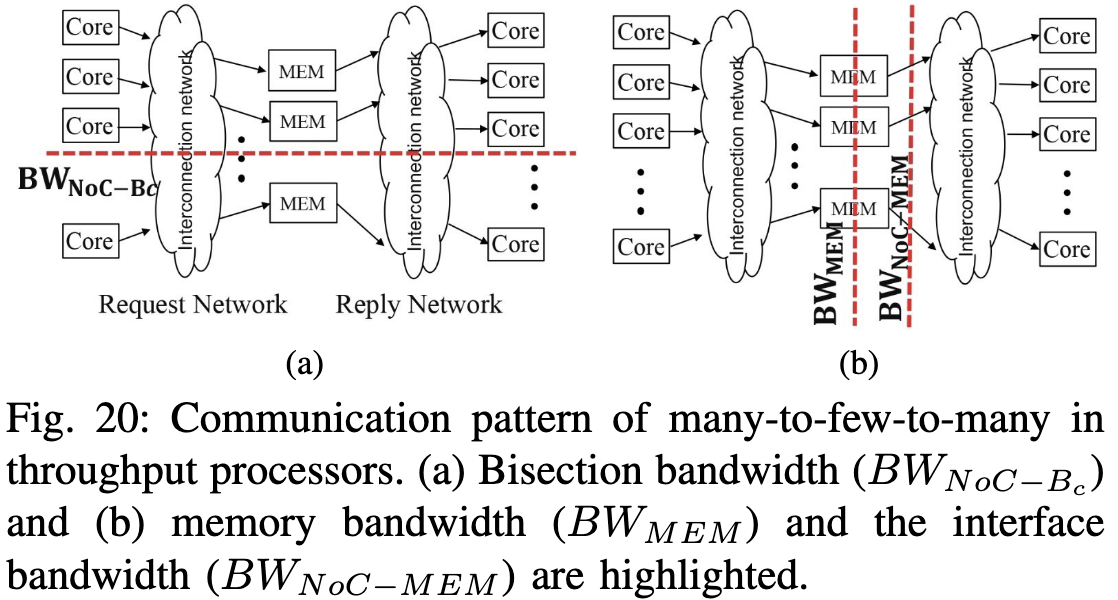
NoC可以分为两部分, reqeust即SM发送到Memory的流量和reply即Memory回复的流量, 一般request比较小而reply很大。三个指标 request-reply回路的带宽$BW_{NoC-B_c}$, 内存带宽$BW_{MEM}$ 和NoC带宽 $BW_{NoC-B_c}$, 用来衡量瓶颈。作者在GPU上执行以前的模拟器benchmark kernel发现memory utilization并没有那么低。作者也明说了不正确的NoC假设会影响整个系统带宽的分析。
感觉还是trade-off的艺术。
Network-on-Chip, 片上网络, 在超多核处理器中实现core对各资源的accessbility, QoS和scalability。 ↩︎
指SM-L2和SM-SM之间的通信 ↩︎
NV文档并没有该词(或者是我没找到) ↩︎
其实也还是L2 cache ↩︎
This work does not completely reverse-engineer the GPU NoC architecture or the memory hierarchy ↩︎
这么讲可能有点抽象。$GPC_{l}$是TPC-GPC间的speedup, $GPC_{g}$是GPC内所有SM并发的speedup ↩︎
应该比较直观, 因为不同request访问访问相同cacheline时可以通过广播来减少实际cacheline访问 ↩︎
只需知道不同byte在解密时候的unique cacheline request的分布 ↩︎