Info
本文作者是University of Helsinki的Haining Tong。
端午快乐!拖了那么久才写出来 读了好几遍才看懂, 要重修离散和OS了
这篇也是老板推荐的今年的asplos中的一篇, 学习一下GPU的Consistency Model。
这篇work用形式化(SMT)的方法对NV的PTX和Vulkan的Consistency Model进行分析,
给出了一个魔改CPU Consistency分析的框架Dartagnan并用.cat语言描述GPU
Consistency Model, 顺便用这个框架发现了两个bug, 还是挺神奇的。
这篇工作首次提出了一个分析GPU代码consistency的框架, 通过迁移CPU上成熟的方案 到GPU上, 能保证model的正确性。
Motivation
虽然CPU上已经有很多成熟的并行一致性分析工具了, 但GPU上几乎没有相关的研究和工具。 现有的工作只给出了理论上的GPU一致性模型和伪代码, 并没有针对现有的GPU编程模型。同时, 由于GPU是强并行的, 其一致性模型也比CPU更复杂, 需要一个新的分析框架来处理。
一个典型的GPU race condition的例子是 XF inter-workgroup barrier
__kernel void xf_barrier(global atomic_uint *flag , global uint* in, global uint* out) {
in[get_global_id(0)] = 1;
if (get_group_id(0) == 0) {
if (get_local_id (0) + 1 < get_num_groups (0)) {
while (atomic_load(&flag[get_local_id (0) + 1]) == 0);
}
barrier(CLK_GLOBAL_MEM_FENCE); // (4)
if ( get_local_id (0) + 1 < get_num_groups (0) ) {
atomic_store (& flag [ get_local_id (0) + 1] , 0) ;
}
} else {
barrier ( CLK_GLOBAL_MEM_FENCE ); // (1)
if ( get_local_id (0) == 0) { // (2)
atomic_store (& flag [ get_group_id (0) ], 1) ;
while ( atomic_load (& flag [ get_group_id (0) ]) == 1) ;
}
barrier ( CLK_GLOBAL_MEM_FENCE ); // (3)
}
for ( unsigned int i = 0; i < get_global_size (0) ; i ++) {
out [ get_global_id (0) ] += in [ i ];
}
// assert ( out [ get_global_id (0) ] == get_global_size (0) );
}
这段代码中, work group 0 是 leader, 负责协调其他 work group 的执行, 其他 work group 会有 follower threads, 然后 follower threads 也有 thread 作为 leader。内存屏障的作用是: (1) 保证所有的 follower 都到达此处, 然后 (2) follower threads 中的 leader 会设置一个 flag 通知它的上级 leader thread, 然后spin lock等待它上级的指示, (3) 其他follower threads 等待它们 的leader指示。
在leader group中, 每个thread都会负责跟follower threads的leader进行通信。它先等待 (2) 处 它负责的follower threads的leader设置flag, 然后 (4) 处等待所有的leader group的threads 完成, 最后释放follower threads的leader, 通知他们可以开始执行了。
这段代码看起来很美好, 但这是作者修正之后的代码。原版代码的所有store/load都是非原子的, 导致在不同的
GPU中可能有data race condition使得程序行为不可预测, 这段代码也会变得不可移植。那怎么办呢?分析
可能会存在的一致性问题, 然后加锁, 问题解决。
Background
需要的前置知识还挺多, 慢慢看
.cat
形式化验证嘛, 肯定要搞点形式化语言, 于是就用.cat语言来描述GPU的Consistency Model。它包含
$$ \begin{aligned} mm &::= def \mid axm \mid mm \land mm \newline axm &::= \text{acyclic}(r) \mid \text{total}(r) \mid \text{transitive}(r) \newline def &::= \text{let} d:=r \mid \text{let} d:=s \newline r &::= b \mid d \mid r^{-1} \mid r;r \mid r \cap r \mid r \cup r \mid r \backslash r \newline b &::= \text{po} \mid \text{rf} \mid \text{co} \mid \text{loc} \mid [t] \mid t \times t \mid \cdots \newline s &::= t \mid d \mid s \cup s \mid s \cup s \mid s \backslash s \newline t &::= \mathbb{I} \mid \mathbb{W} \mid \mathbb{R} \mid \mathbb{F} \mid \mathbb{B} \mid \cdots \end{aligned} $$
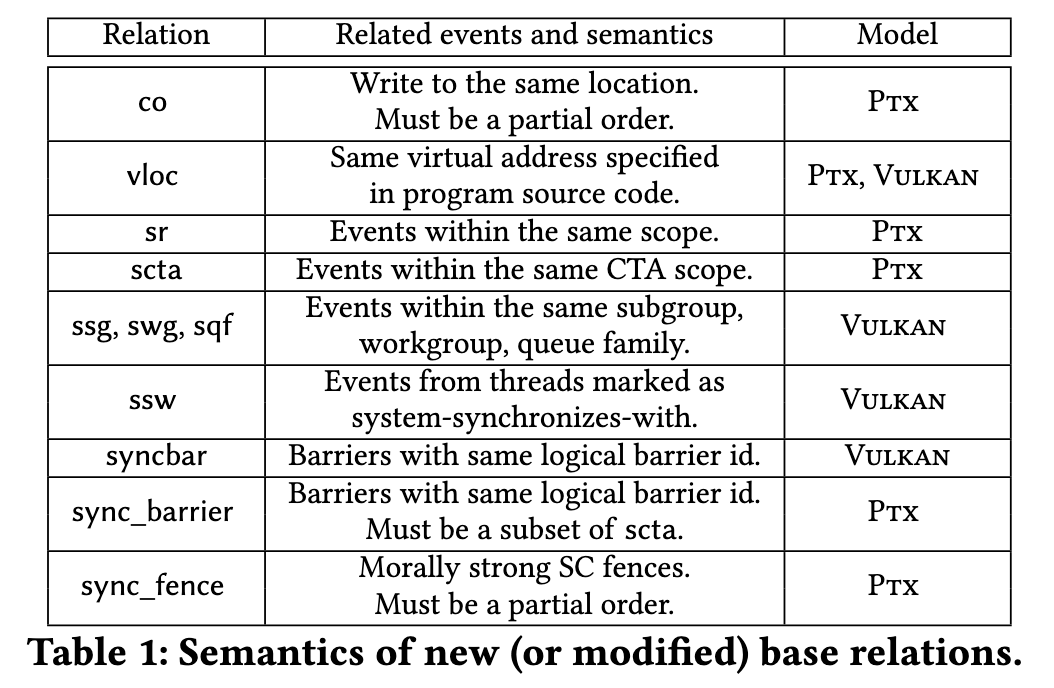
有点抽象。r 是 memory event relation 然后 b 是其 base relation, 包括 program order $\text{po}$ 即程序执行顺序, read-from $\text{rf}$ 表示读操作从哪个写操作读取数据, coherence order $\text{co}$ 表示内存写顺序, location $\text{loc}$ 表示操作相同的内存位置。除了union, intersection 和 difference, 还可以对这些关系进行逆转 $r^{-1}$, 连接 $r;r$,以及定义def。
s 是 memory event tag, t 是 base event tag 即 write $\mathbb{W}$, read $\mathbb{R}$, fence $\mathbb{F}$, barrier $\mathbb{B}$ 和 writes populating initial memory value $\mathbb{I}$。接着 s 可以拓展 t 到一些组合的 tag, 比如 read-write $s = \mathbb{R} \cup \mathbb{W}$, fence-barrier $\mathbb{F} \cup \mathbb{B}$ 等等。
Program and Behavior
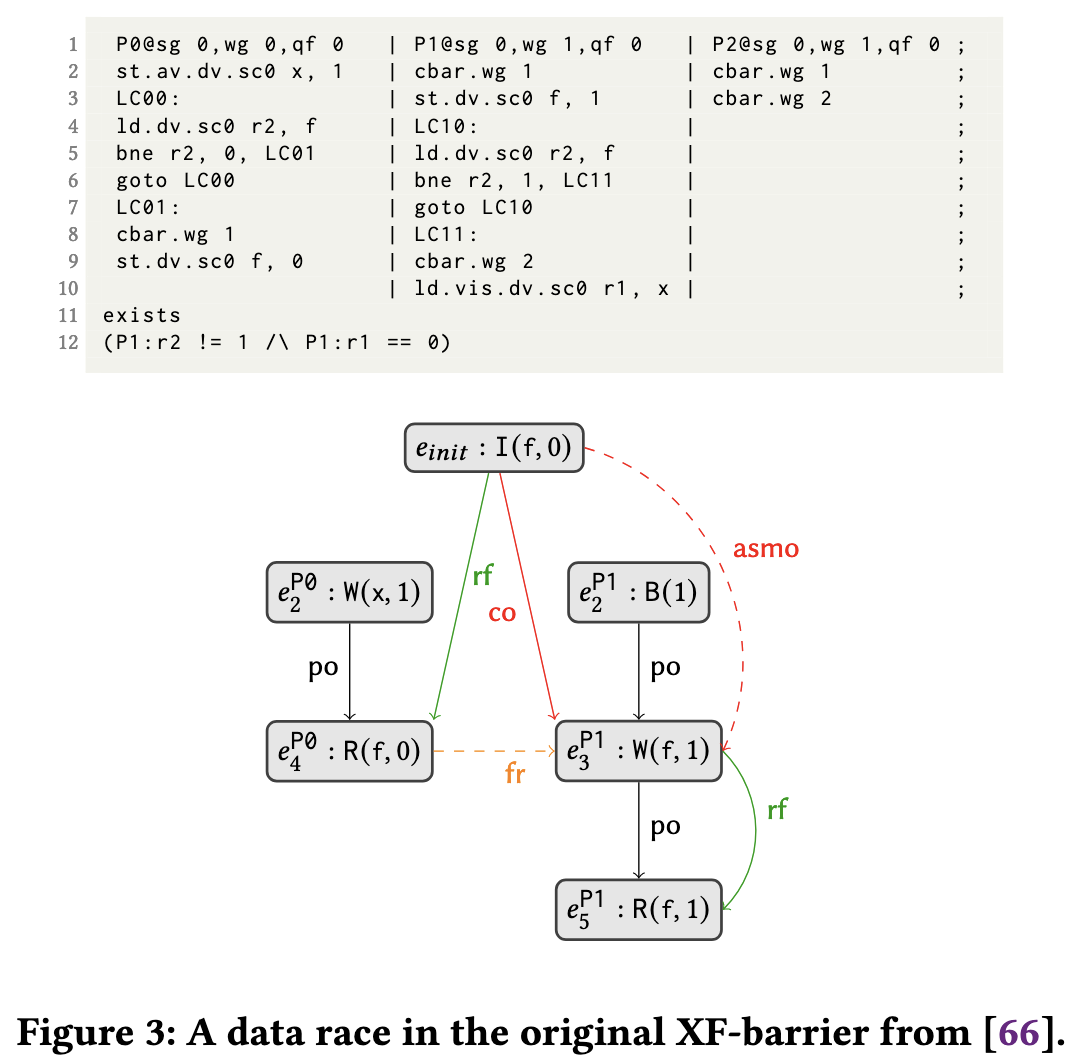
这是原版的 XF barrier 用 litmus 描述的形式。程序的每一列表示执行的thread, 如 P0, P1, P2。第一行是它们的metadata,
如所属的work group。剩下的就是代码, ld 表示 load 操作, st 表示 store 操作, memory label (eg LC00) 表示内存位置,
以及 bne 分支操作, goto 跳转操作和 cbar 控制屏障操作。最后以exists或forall结尾, 类似assert。
并行程序的弱一致性行为(weak behavior)会同时读写同一块内存, 用形式化语言就是一个tuple$(\mathbb{X}, \text{rf}, \text{co})$, 即 executed events, read-from relation 和 coherence order relation。Behavior 必须是 well-defined 的, 即
- events 必须表示合法的控制流
- read 必须来自于某些 write 操作 (没写就读读了个寂寞)
- rf 和 co 的目标必须是相同的 (要不然这俩玩意不相关又有什么意义)
- $\mathbb{I}$ 的 write 必须在 co 的开头
- 当目标地址是同一个的时候, co 必须是 total order 的
读起来可能有点懵逼,其实看完文章就明白了。图中的节点是events, 即内存操作, 边是relation。然后fr和asmo是一些新推出的关系, 可以先忽略。
e 表示 event, 有所属进程(比如P0)和行号(比如$e_2$)。图中, $e_2^{P0}$ 与 $e_{\text{init}}$ 是 rf 关系, 对应 leader thread 不停 地检查 flag (f in expression R(f, 0) and W(f, 1)); $e_3^{P1}$ 与 $e_{\text{init}}$ 是 co 关系, 即 follower leader 写入 flag 的操作。
Bounded Model Checking
假设你熟悉SAT, 不懂的话重修数理逻辑。
Bounded Model Checking (BMC) 就是用形式化的手段, 叫做 SMT (Satisfiability Modulo Theories) 来验证程序的行为。
SMT 能推导出程序运行之后的一些结果, 比如执行a = 1 + 1之后我们可以推导出a = 2, 然后检查条件是a < 3, 如果能推
导出a < 3为真, 那么就说明程序是正确的。当然, 推导就是用 SMT 求解器来做的, 并非人类手动推导。
GPU Consistency
因为GPU架构跟CPU架构有很大不同, 所以GPU的Consistency Model也跟, 这里就大概介绍一下GPU的Consistency Model。
Memory Scopes
GPU 有两种内存scope, 一种是CPU划分给GPU的, 主要用于数据传输, 另一种是GPU内部的全局内存。因为容量和延迟的原因, GPU倾向于用 其内部的HBM, 并且有更近一步的scope层级划分。最低一级的scope只允许相同thread array中的线程或是work group scope中的线程访问, 最后是global scope。中间可能还有更细致的scope, 以及还可能有更大的、与其他accelerator共享的scope。
Scope的概念最早来自于Heterogeneous Race Free (HRF) Model, Nvidia的PTX和Vulkan都基于这个模型。PTX 的 scope 分为 CTA (compute thread array), GPU (global scope) 和 SYS (system scope); Vulkan 的 scope 分为 Subgroup, Workgroup, Queue Family 和 Device。Vulkan 没有与system共享的scope, 但有 system-synchronizes-with 的概念。
Memory Fences and Control Barriers
GPU 提供了更细致的 fence 和 barrier 操作, 以便更好地控制内存访问和线程同步。fence 使得memory access是同步的, 即按顺序进行的; barrier 保证程序执行是同步的, 比如如果有线程比其他线程快, 它会在 barrier 处等待其他线程到达。PTX 和 Vulkan 都有内存屏障。 大多数GPU能提供 work group 级别的 barrier, Vulkan 还能通过 barrier 来同步内存访问。
Address Spaces
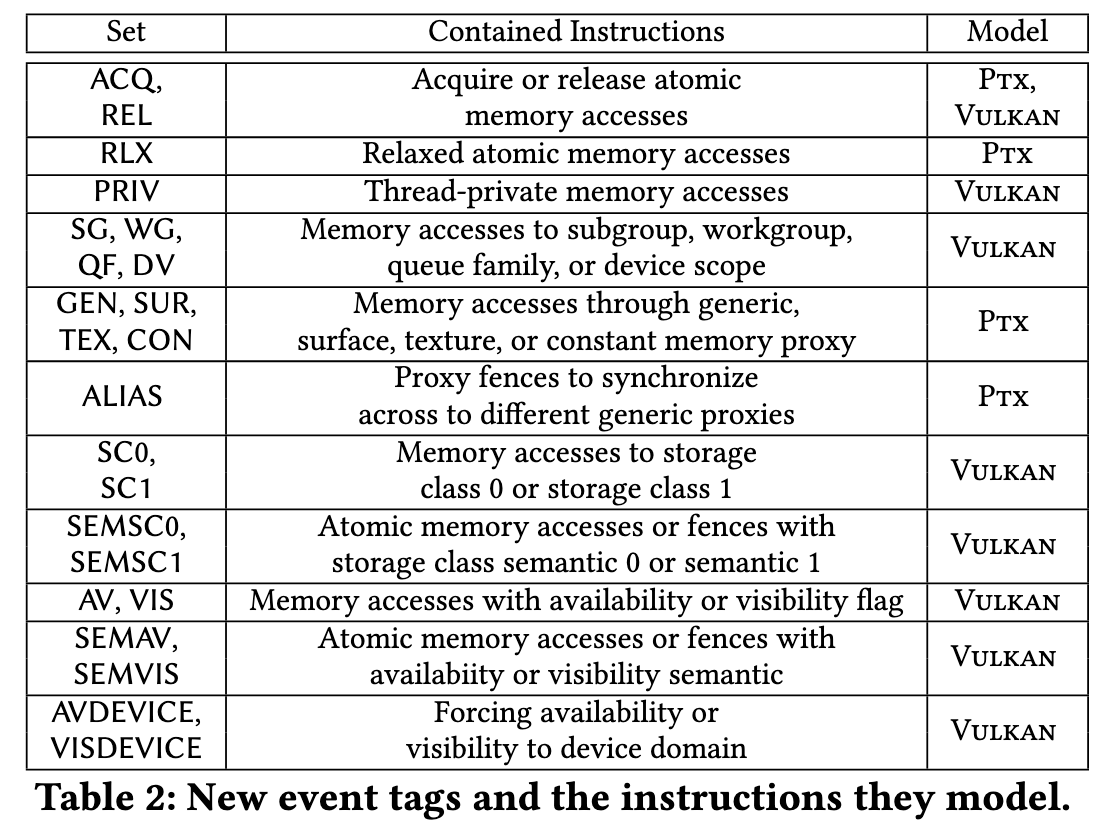
GPU 肯定也有 cache, 但是 NV 搞了个更抽象的概念 proxy, 用来加速surface and texture graphics等等, 这个概念让thread不知道 自己在访问memory还是specialized cache, 也方便GPU来管理不同的cache和memory (因为它们结构不同)。但是这个概念让 consistency model 变得更复杂。Proxies 有四种:
- GEN (generic proxy): 访问全局内存, 也就是 GPU 的 HBM
- TEX (texture proxy): 访问纹理内存, 也就是 GPU 的纹理缓存
- SUR (surface proxy): 访问表面内存, 也就是 GPU 的表面缓存
- CON (constant proxy): 访问常量内存, 也就是 GPU 用来存配置信息的内存
然后针对不同的 proxy, GPU 提供了不同的内存屏障, 需要注意没有GEN的屏障, 而被替换为alias-proxy fence, 即针对访问同一内存但通过不同proxy访问的 屏障。textureproxy, surface-proxy, and constant-proxy fences 用来与 GEN proxy 进行同步。
Vulkan 是用 Storage Class 来区分 memory 和 cache 的访问。在 formal model中, 这些复杂的storage class 被抽象为两种
sc0 或 sc1 来区分访问的内存类型。同时, 还定义了 Storage Class Semantics 用来作为 barrier 和 fence 的语义,
也被抽象为semsc0 和 semsc1。
Availability and Visibility
PTX 的 semantics 能保证一个线程的store操作能被另一个thread看到, 但是Vulkan不能。所以Vulkan引入了availability和visibility的概念。 Availability 表示让一个内存中的变量在特定的cache中能被访问 (表示我写完啦, 你读吧), visibility 表示线程可以感知到某个变量在cache中 (即我读过这个变量)。Availability 只与write操作有关, 而 visibility 只与 read 操作有关。Atomic 操作原本就具备这两种语义, 但非原子操作需要通过指定语义来保证。
Availability 和 visibility 可以被强制设定, 而且方法是类似的。如果一个变量用non-atomic write 操作写入, 那么可以用一个fence或者 atomic write 就可以让这个变量可见。
Data Races
Data race 指的是两个线程同时写入同一内存位置, 如果它们的值不一样, 那最终写入哪个值是不确定的, 导致程序行为不可预测。 这个问题很重要, 但是PTX并不考虑程序是否是 Data-Race Free (DRF) , Vulkan 表示这是 undefined behavior, 但必须由程序员来保证。
Formal Models
不同的GPU有不同的tags和relations, 无需多言。
PTX Consistency Model
废话少说, 直接看代码。这个是作者给出比较关键的代码
// (* Proxy *)
let sameProx = GEN * GEN | SUR * SUR | TEX * TEX | CON * CON
let povloc = po & vloc
let co = co+
let fr = rf^-1; co
// (* Morally-strong *)
let ms1 = (po | po^-1) | ([strongOp]; sr; [strongOp])
let ms2 = sameProx
let ms3 = ((M * M) & vloc) | ((_ * _) \ (M * M))
let ms = (ms1 & ms2 & ms3) \ id
// (* Proxy-aware causality ordering *)
let pxyFM = [F]; (sameProx & scta); [M]
let proxyPreservedCauBase =
( [GEN]; (vloc & cauBase); [GEN])
| ([M]; (sameProx & scta & vloc & cauBase); [M])
| vloc & (cauBase & (pxyFM^-1); cauBase; [GEN])
| vloc & ([GEN]; cauBase; cauBase & pxyFM)
| vloc & (cauBase & (pxyFM^-1); cauBase; cauBase & pxyFM)
| loc & ([GEN]; cauBase; [F & ALIAS]; cauBase; [GEN])
| loc & (cauBase & (pxyFM^-1); cauBase; [F & ALIAS]; cauBase; [GEN])
| loc & ([GEN]; cauBase; [F & ALIAS]; cauBase; cauBase & pxyFM)
| loc & (cauBase & (pxyFM^-1); cauBase;
[F & ALIAS]; cauBase; cauBase & pxyFM)
let cause = observation?; proxyPreservedCauBase
// (* Axioms Coherence *)
empty ((([W]; cause; [W]) & loc) \ co)
empty (([W]; ms; [W]) & loc) \ (co | co^-1)
// (* Axiom FenceSC *)
empty (([F & SC]; cause; [F & SC]) \ sync_fence)
// (* Axiom Atomicity *)
empty (((ms & fr); (ms & co)) & rmw)
// (* Axiom No-Thin-Air *)
let dep = addr | data | ctrl
acyclic (rf | dep)
// (* Axiom Causality *)
irreflexive ((rf | fr); cause)
PTX 6.0 没有 proxy, proxy的引入是在 7.5。然后作者的解决方案就是定义sameProxy, 因为
same proxy的保证和generic memory是一样的。
这里的axiom其实就是assert, 也就是一些SMT的约束条件。太长了就不一一解释了。然后是一个应用例子, 叫 Message Passing over different proxies, 也就是不同的proxy之间的通信。
{
y @ generic aliases x;
s @ surface aliases x;
t @ texture aliases y;
}
P0@cta 0,gpu 0 |P1@cta 0,gpu 0 ;
sust.weak s, 1 |ld.acquire.cta r0, flag ;
fence.proxy.surface |fence.proxy.alias ;
st.release.cta flag, 1 |fence.proxy.texture ;
|tld.weak r1, t ;
~ exists
(P1:r0 == 1 /\ P1:r1 != 1)
首先给出了三个alias和它们所处的proxy与真实位置(x)。这个例子中 P0 给 P1 发送了一个消息, sust.weak s, 1
表示 P0 在 surface proxy 上写入了 1, 然后用fence.proxy.surface 来保证 s 的可见性, 然后 P1 通过
ld.acquire.cta r0, flag 加锁并从t中读取了1。因为保证P1在P0写入之后才读到值, 所以结尾的条件成立。
还有其他例子就不一一展示了。
需要注意的是, PTX 不要求 co 关系是 total order 的, 只需保证是 partial transitive order 即可。如果 要求 total order, 可以用 atomic write 或者用 Axiom Coherence 来保证。对于morally strong保证, 只需确保
- 程序按顺序执行或操作是strong的 (即用fence或者atomic操作),并且是sr (in the same scope)
- 同一个proxy
- 如果都是memory操作, 它们用的是同一个virtual address (vloc)
Vulkan Consistency Model
Vulkan 的 consistency model 也差不多, 但有一些不同的地方, 比如 PTX 允许 weak store (即 store 顺序不保证是po), 但是 Vulkan 认为这会导致 data race, 所以要强化 co 变为 asmo (scoped modification order)
let asmo = co & ((A | IW) * A)
还有一个奇怪的问题, happen-before relation 并不是 transitive 的, 例如
![]()
里面的.sc1 等等semantics 确保了
$$ e_2^{P0} \xrightarrow{\small{hb}} e_3^{P0} \xrightarrow{\small{hb}} e_2^{P1} \xrightarrow{\small{hb}} e_3^{P1} \xrightarrow{\small{hb}} e_3^{P2} \xrightarrow{\small{hb}} e_2^{P2} $$
但是这不是transitive的, 即$e_2^{P2}$ 观测不到 $e_2^{P0}$ 的写入。所以我们要加入一个.semav语义, 用
let avwg = (chains & ([AVSG]; (hb & ssg & avinc))?); [AVWG]]
// ...
let vissh = [VISH]; (chains & (((hb & sqf & avinc); visqf)?;
((hb & swg & avinc); viswg)?; ((hb & ssg & avinc); [VISG])?))
来保证。
Understanding the Models
这一节讲他们发现的两个bug。第一个是编译器优化的bug
P0@sg 0,wg 0, qf 0 | P1@sg 0,wg 1, qf 0 ;
st.atom.dv.sc0 data, 1 | LC00: ;
membar.rel.dv.semsc0 | ld.atom.dv.sc0 r1, flag ;
st.atom.dv.sc0 flag, 1 | membar.acq.dv.semsc0 (-) ;
| bne r1, 0, LC01 ;
| goto LC00 ;
| LC01: ;
| membar.acq.dv.semsc0 (+) ;
| ld.atom.dv.sc0 r2, data ;
| ld.atom.dv.sc0 r3, 1 ;
exists
(P1:r3 == 1 /\ P1:r2 != 1)
一般来说没什么问题, 但是编译器发现 acquire 在 spin-loop 里面, 会把它挪到外面去; 更有甚者, NIR 编译器会把 spin-loop 优化掉,因为里面没有 barrier, 这肯定不对啊。作者讲原因归为Vulkan的 memory model不够完善以及compiler engineer对于 memory model 的理解不够深入。
另外一个是PTX的deque。每个CTA都有一个work deque, 但是如果一个CTA的work deque没东西, CTA会 拿别的CTA的work deque的东西来执行。本来没啥问题, 但是搞笑的是deque的代码没用fence, 导致当CTA 拿别的deque的内容的时候, 队尾指针t是对的, 但是里面的数据是入队前的。
P0@cta 0,gpu 0 | P1@cta 1,gpu 0 ;
st.relaxed.gpu d, 1 | ld.weak r0, t ;
fence.sc.gpu | beq r0, r3, LC00 ;
ld.weak r2, t | fence.sc.gpu ;
add r2, r2, 1 | ld.relaxed.gpu r1, d ;
st.weak t, r2 | LC00: ;
exists 8 (P1:r0 == 1 /\ P1:r1 == 0)
原因就在于PTX的memory model并不保证强内存序。忽略上面的fence你就能明白是为什么了。 这个例子跟MP是一样的, 不懂内存序的程序员有难咯。
Analysis Framework
这节主要讲他们的框架是怎么实现的。但是一堆公式以及跟软件分析相关所以就先不看了。有空再写。
Discussions
因为实验结果没啥好看的就先略过了。这一节主要在argue为什么这篇文章有意义 (kind of rebuttal), 也略过。